The Pipeline
Before answering, a lightweight router selects the best reasoning paradigm for each task.
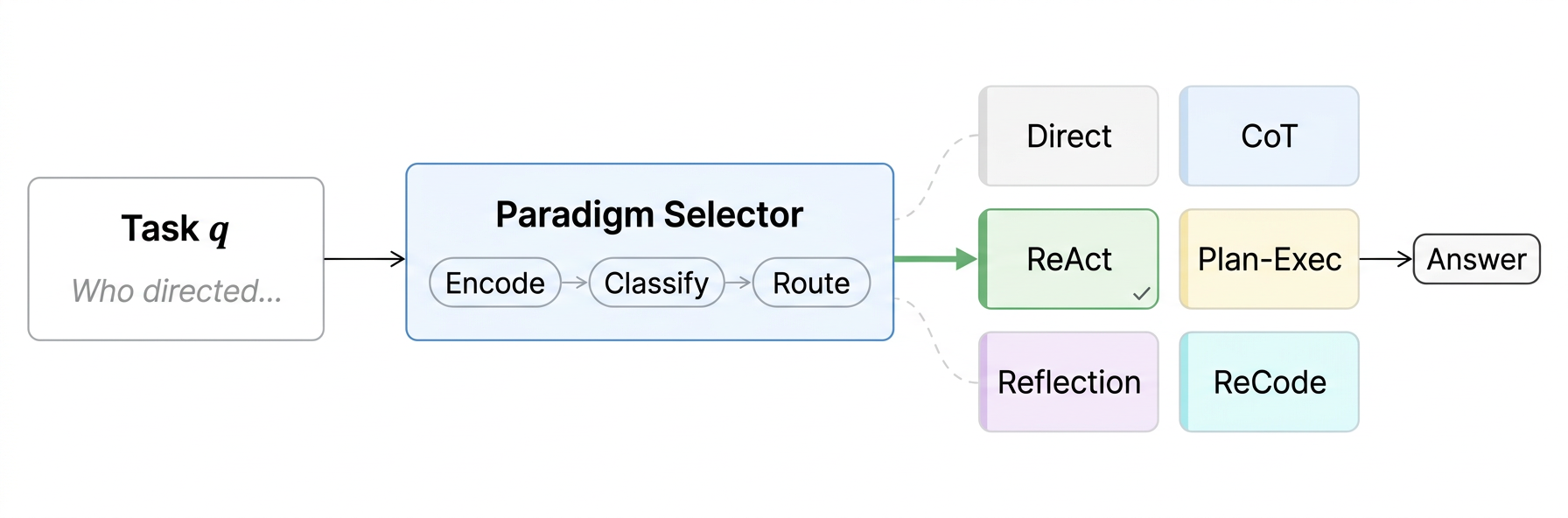
Paradigm Routing as Inference-Time Optimization for LLM Agents
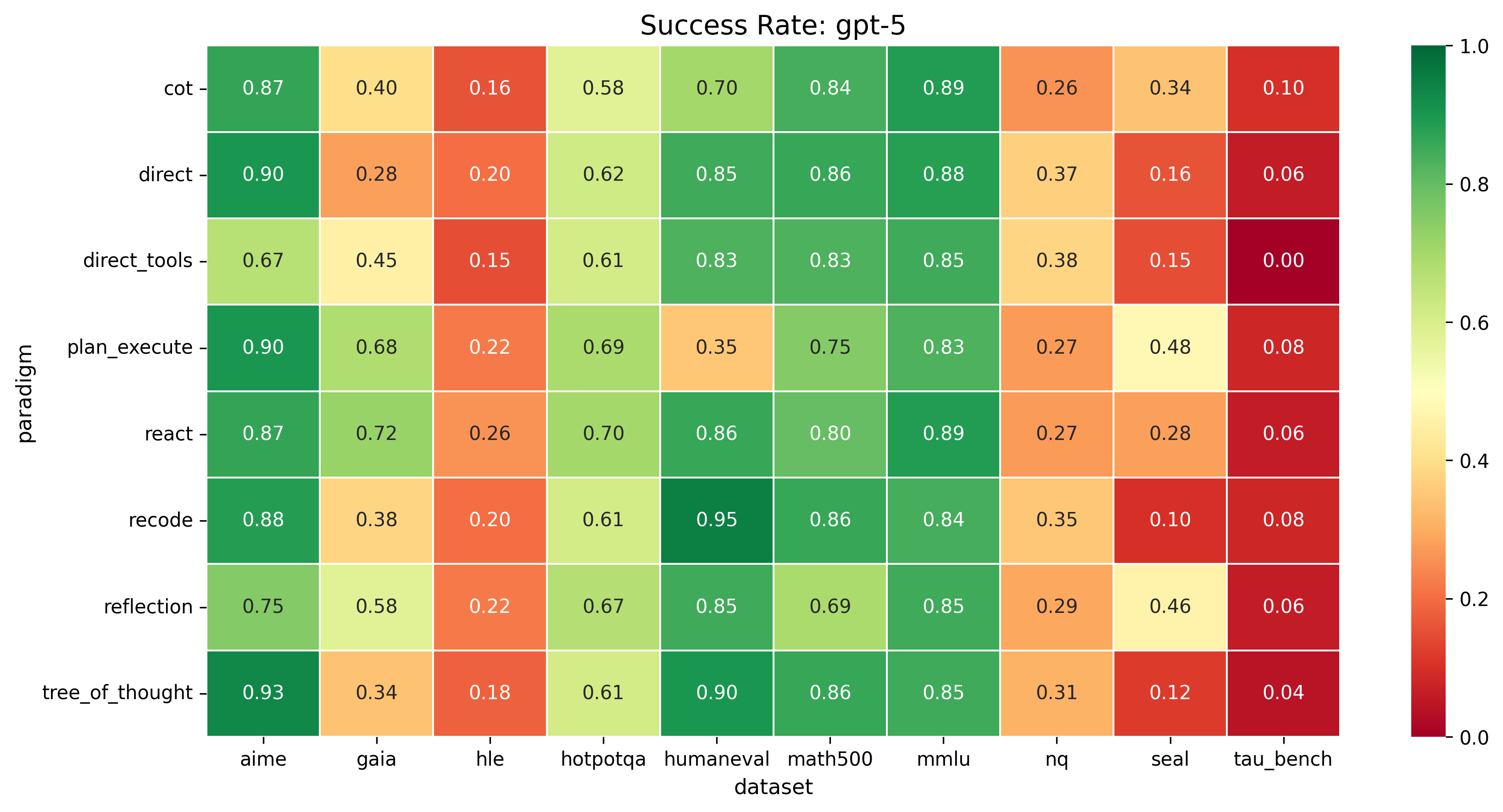
We compare 6 reasoning paradigms across 4 frontier LLMs and 10 benchmarks (~18k runs). No single paradigm wins everywhere.
Our embedding-based router selects the best paradigm per task, improving accuracy from 47.6% to 53.1% and recovering up to 37% of the oracle gap at half the token cost of always using ReAct.
Models cannot select their own paradigm: zero-shot self-routing fails for weaker models, revealing paradigm selection as a distinct meta-reasoning capability.
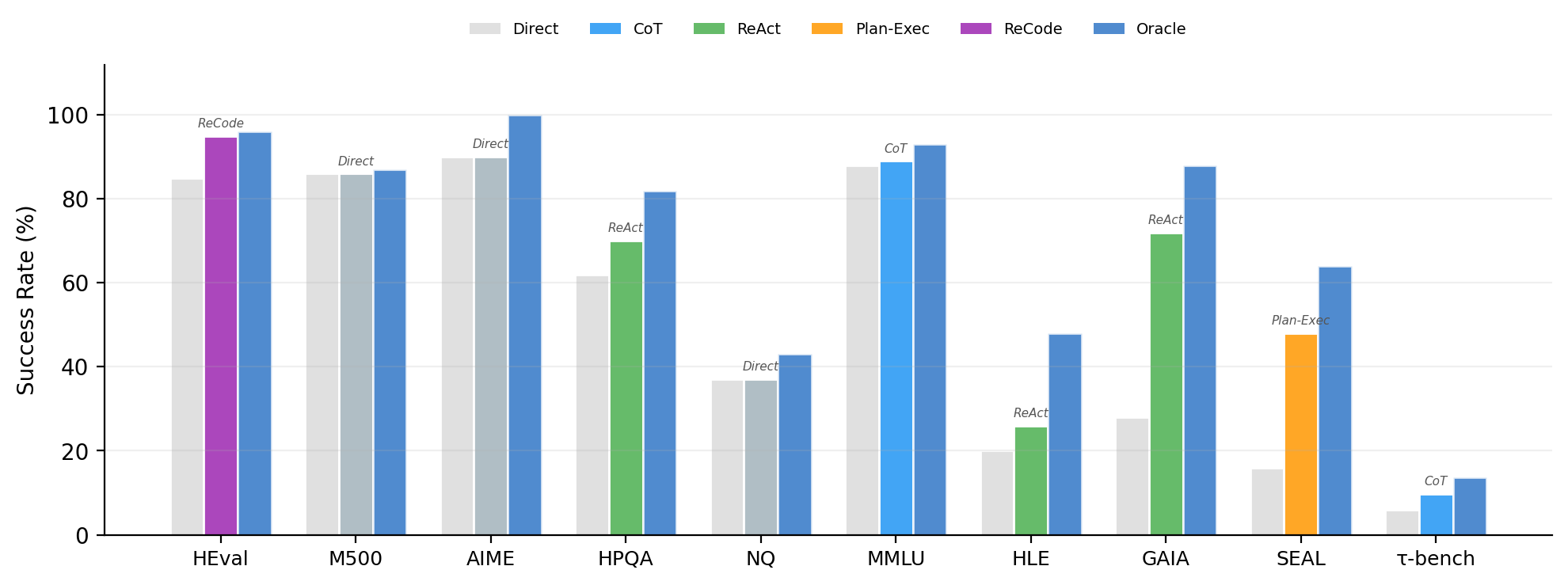
ReAct improves over Direct by 44pp on GAIA where web search is essential.
CoT degrades HumanEval by 15pp because step-by-step reasoning disrupts code generation.
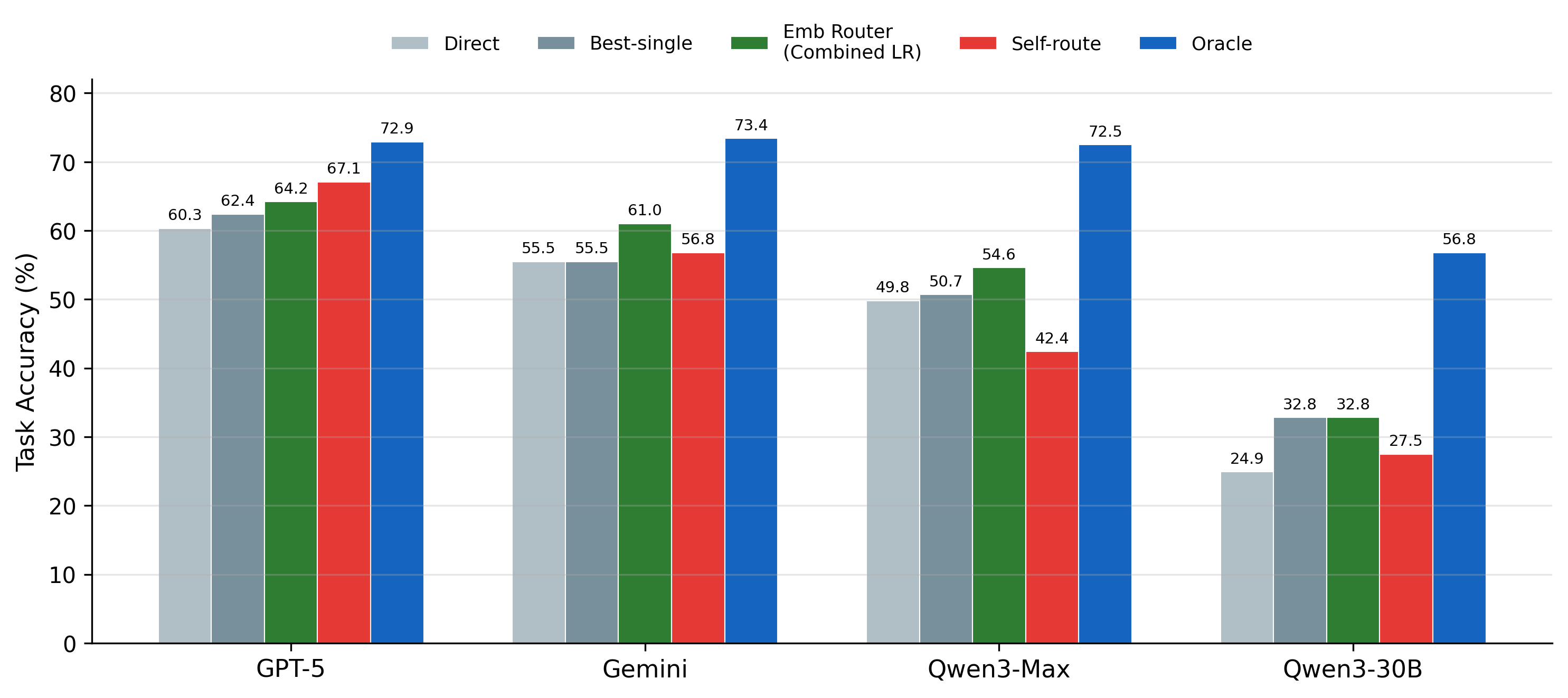
Embedding router improves 5.5pp over Direct and 2.8pp over best fixed paradigm across 4 models.
GPT-5 can self-select at 67.1%, but weaker models fail, all trailing the learned router.
Before answering, a lightweight router selects the best reasoning paradigm for each task.
Direct vs. best paradigm vs. oracle on each dataset for GPT-5. The best paradigm (colored) differs for every task type.
The embedding router (green) consistently outperforms Direct and Best-single. Self-routing (red) shows mixed results.
Success rates across all paradigms and datasets. No single row dominates all columns.
Free-form answer. No scaffold imposed. The model decides how to reason.
Step-by-step reasoning before answering.
Interleave reasoning with tool calls in a thought-action loop.
Create a plan first, then execute each step with tools.
Answer, critique, and revise iteratively.
Solve via recursive code generation and execution.
| Method | GPT-5 | Gemini | Qwen3-Max | Qwen3-30B | Avg |
|---|---|---|---|---|---|
| Direct | 60.3 | 55.5 | 49.8 | 24.9 | 47.6 |
| Best-single | 62.4 | 55.5 | 50.7 | 32.8 | 50.3 |
| Embedding Router | 64.2 | 61.0 | 54.6 | 32.8 | 53.1 |
| Self-route | 67.1 | 56.8 | 42.4 | 27.5 | 48.4 |
| Oracle | 72.9 | 73.4 | 72.5 | 56.8 | 68.9 |