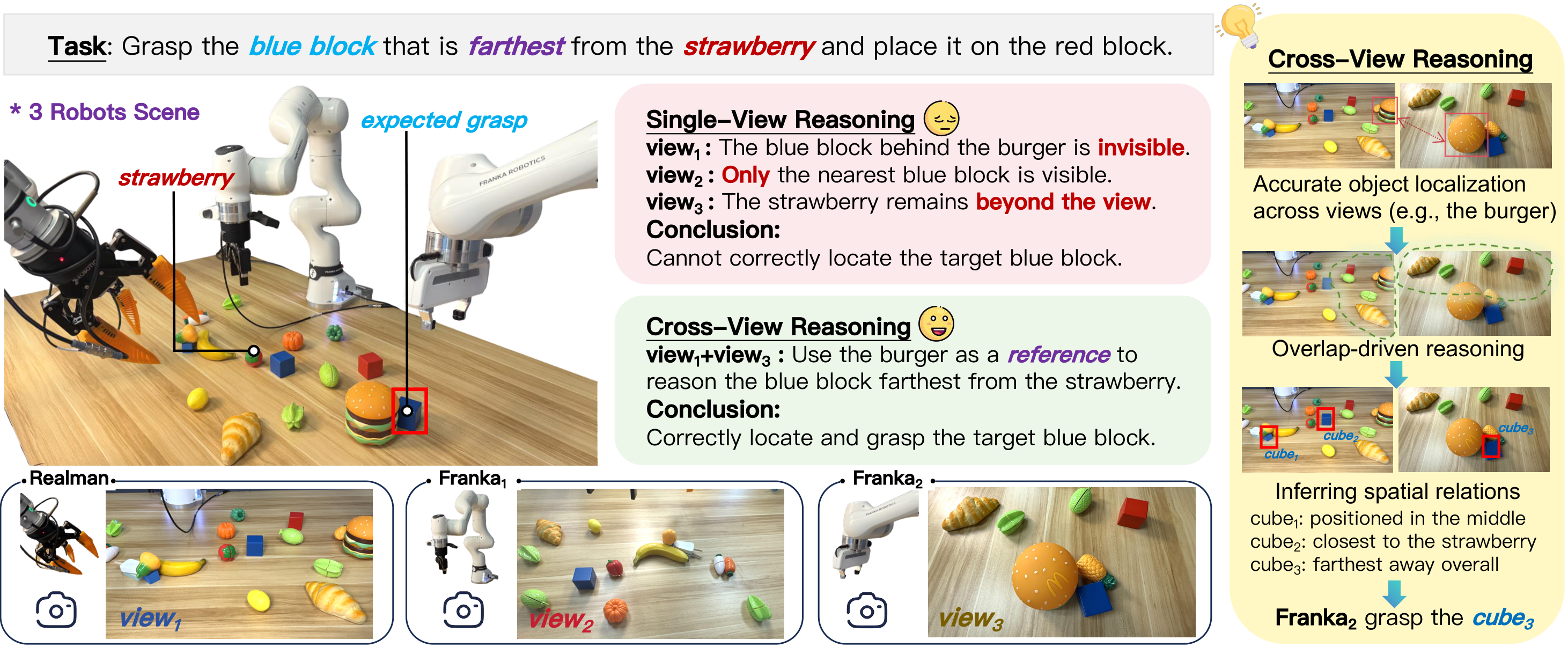
Understanding the world from distributed, partial viewpoints is a fundamental challenge for embodied multi-agent systems. Each agent perceives the environment through an ego-centric view that is often limited by occlusion and ambiguity. To study this problem, we introduce the Ego-to-World (E2W) benchmark, which evaluates vision-language models' ability to fuse heterogeneous viewpoints across three tasks: (i) global counting, (ii) relational location reasoning, and (iii) action-oriented grasping that requires predicting view-specific image coordinates. To address this setting, we propose CoRL, a two-stage framework that combines Chain-of-Thought supervised fine-tuning with reinforcement learning using Group-Relative Policy Optimization. Its core component, the Cross-View Spatial Reward (CVSR), provides dense task-aligned feedback by linking reasoning steps to visual evidence, ensuring coherent cross-view entity resolution, and guiding the model toward correct final predictions. Experiments on E2W show that CoRL consistently surpasses strong proprietary and open-source baselines on both reasoning and perception-grounding metrics. Beyond simulation, CoRL generalizes to external spatial reasoning benchmarks and enables effective real-world multi-robot manipulation.
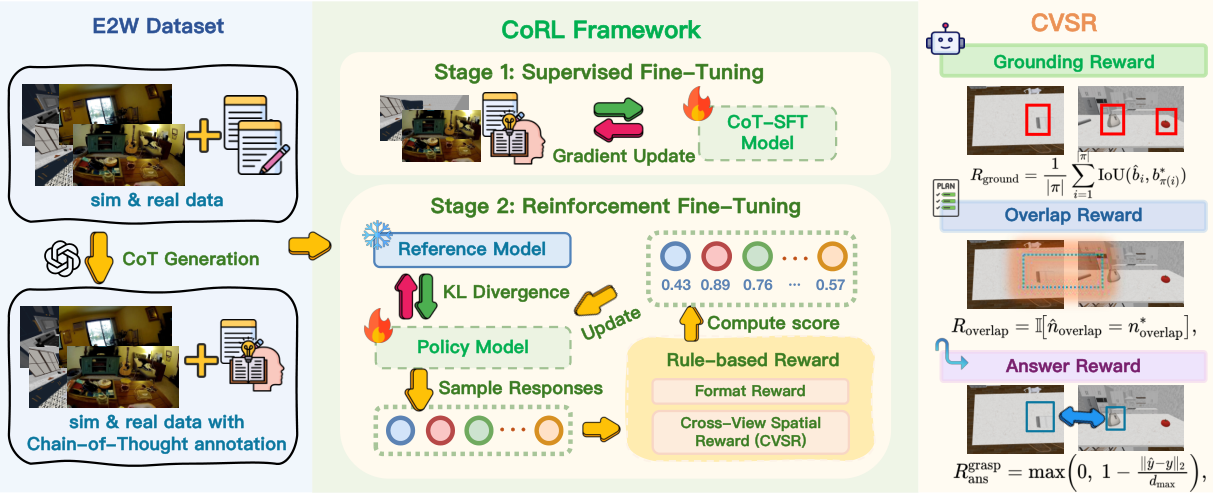
Figure 2. CoRL Framework. Stage 1: SFT with Chain-of-Thought supervision on sim & real data. Stage 2: Reinforcement fine-tuning with Cross-View Spatial Reward (CVSR) — comprising grounding reward (bbox IoU), overlap reward (cross-view entity matching), and answer reward (task-specific accuracy).
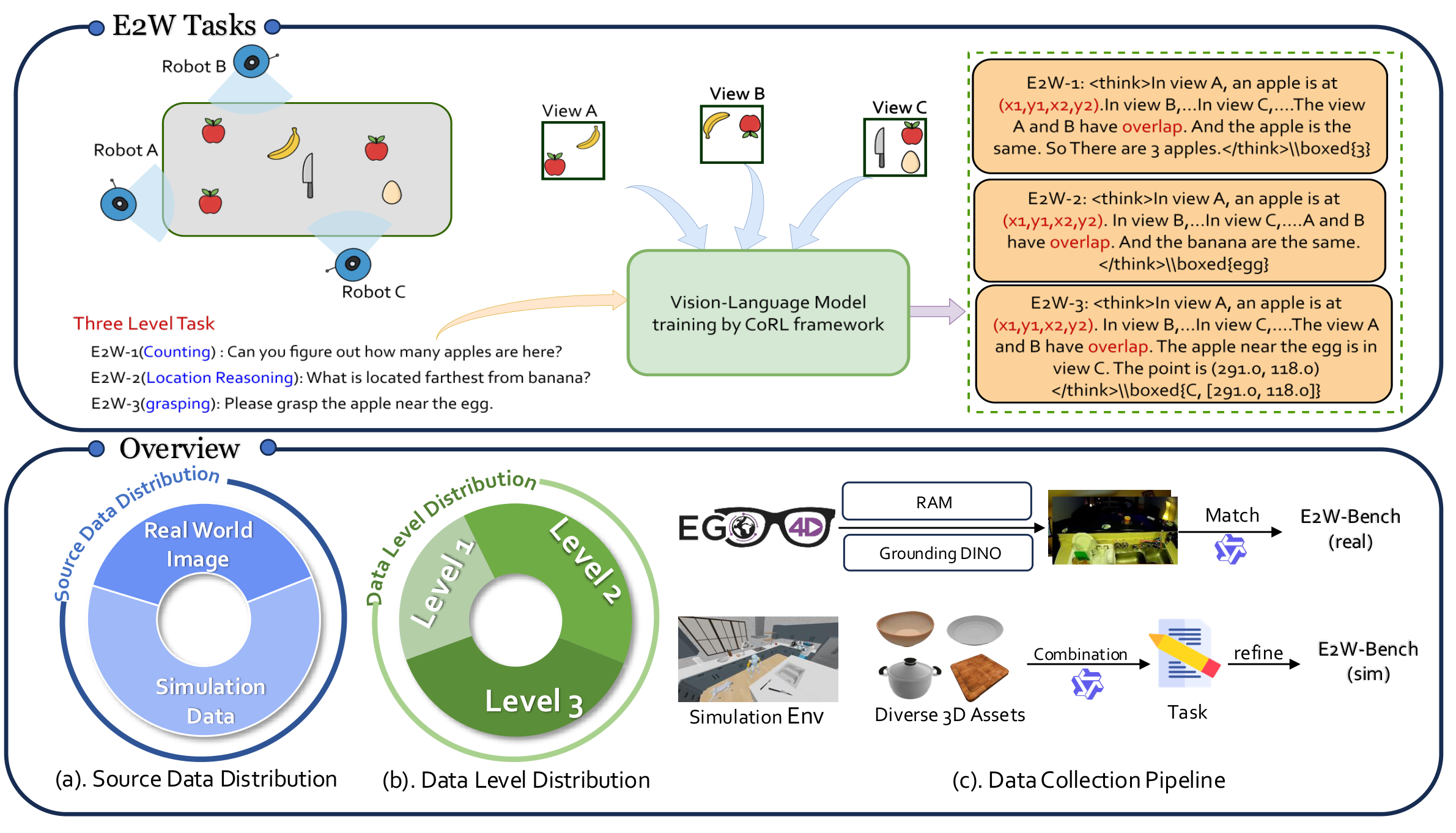
Figure 3. E2W-Bench overview. Three-level tasks with data collected from simulation environments (diverse 3D assets) and real-world robot setups (annotated via RAM + Grounding DINO).
Outputs from Qwen2.5-VL-3B-CoRL on E2W-Bench test set, showing chain-of-thought reasoning with cross-view spatial analysis.






| Model | E2W-1 | E2W-2(S) | E2W-2(R) | Avg. Reasoning | E2W-3(S) | Avg. Perception |
|---|---|---|---|---|---|---|
| Qwen2.5-VL-3B + CoRL | 60.8 | 92.0 | 84.0 | 78.9 | 97.7 | 97.7 |
| Qwen2.5-VL-7B + CoRL | 66.8 | 92.8 | 89.2 | 82.9 | 97.8 | 97.8 |
E2W-1: Object Counting (exact match %) • E2W-2: Spatial Reasoning, (S)im / (R)eal (exact match %) • E2W-3: Grasping, (S)im (proximity score)
@misc{zhou2026egoworldcollaborativespatial,
title={Ego to World: Collaborative Spatial Reasoning in Embodied Systems via Reinforcement Learning},
author={Heng Zhou and Li Kang and Yiran Qin and Xiufeng Song and Ao Yu and Zilu Zhang and Haoming Song and Kaixin Xu and Yuchen Fan and Dongzhan Zhou and Xiaohong Liu and Ruimao Zhang and Philip Torr and Lei Bai and Zhenfei Yin},
year={2026},
eprint={2603.14811},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2603.14811},
}